wlg1
1.1: VAEs
https://www.jeremyjordan.me/variational-autoencoders/ https://towardsdatascience.com/generating-images-with-autoencoders-77fd3a8dd368
To compress an image, an autoencoder consists of two neural networks: an encoder and a decoder. The encoder compresses the image x into a latent code z in latent space Z, and the decoder uses latent code to reconstruct the image. Since the latent space has fewer dimensions than X, the encoder must decide what information to keep, and what to discard.
Instead of mapping each image to a single point in Z, the Variational AutoEncoder (VAE) maps image x onto a probability distribution P(z|X), assigning a probability to every z to find the code z with the highest probability of matching with image x. Since the actual P(z|X) isn’t known, the encoder Q(z|X) approximates P(z|X). Thus the latent space distribution Q(z) is inferred using the image space distribution Q(X).
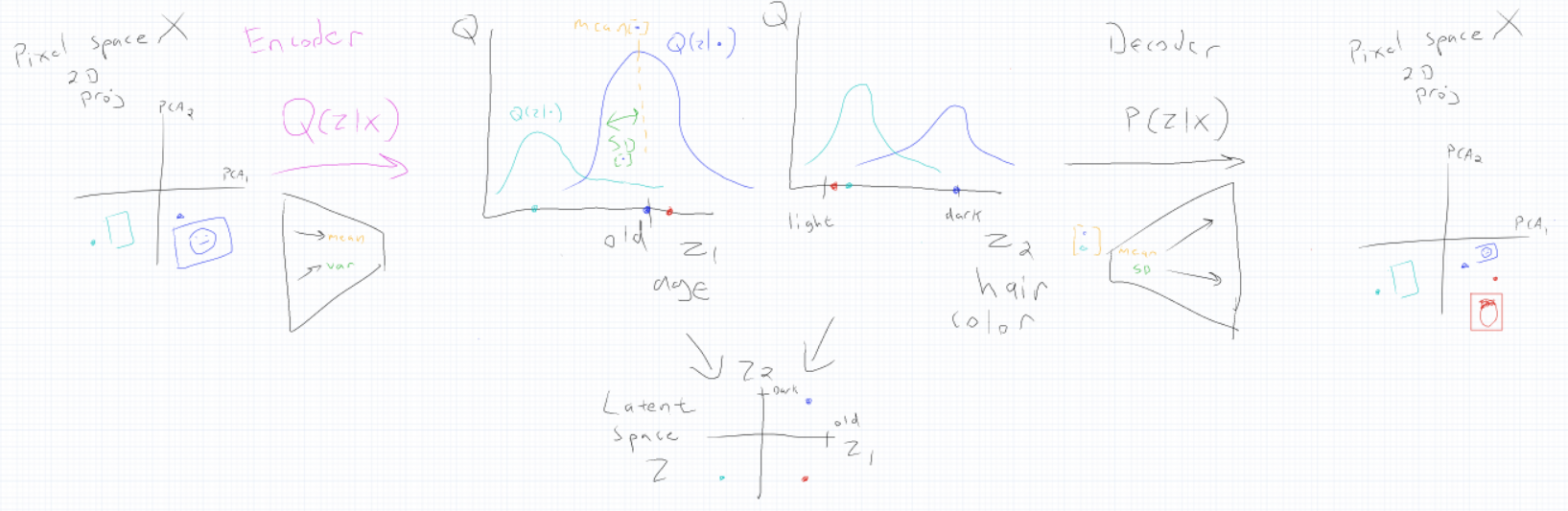
Q(z|X) is represented by learning two vectors: a mean vector and a standard deviation vector. To generate an image with similar features to images that the VAE was trained on, a sample that is close to the distributions of similar images is passed through the decoder.