wlg1

Hello. A selection of my projects can be found below 1. Click on each title link to learn more:
Table of Contents
- Locating Cross-Task Sequence Continuation Circuits in Transformers
- One is 1: Analyzing Activations of Numerical Words vs Digits
- Educational Videos on AI Safety and Neural Network Mathematics
- Machine Learning and Analytics on Social Media Data
- Using Materialized Views for Answering Graph Pattern Queries
Locating Cross-Task Sequence Continuation Circuits in Transformers
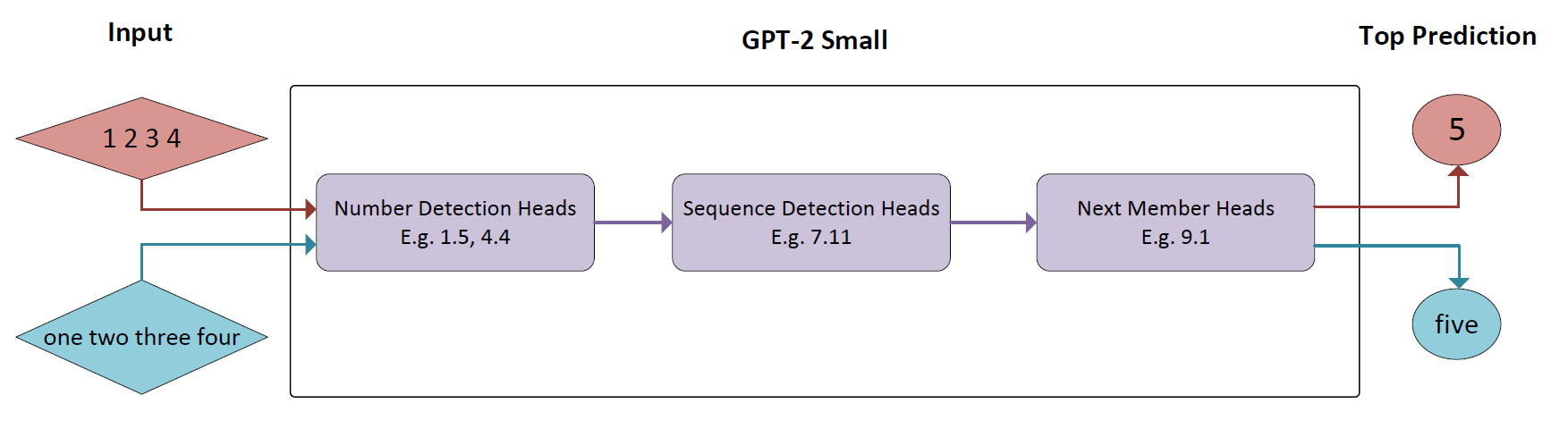
An ArXiV paper that is in the process of being submitted to a conference. The abstract is given as follows:
While transformer models exhibit strong capabilities on linguistic tasks, their complex architectures make them difficult to interpret. Recent work has aimed to reverse engineer transformer models into human-readable representations called circuits that implement algorithmic functions. We extend this research by analyzing and comparing circuits for similar sequence continuation tasks, which include increasing sequences of digits, number words, and months. Through the application of circuit analysis techniques, we identify key sub-circuits responsible for detecting sequence members and for predicting the next member in a sequence. Our analysis reveals that semantically related sequences rely on shared circuit subgraphs with analogous roles. Overall, documenting shared computational structures enables better prediction of model behaviors, identification of errors, and safer editing procedures. This mechanistic understanding of transformers is a critical step towards building more robust, aligned, and interpretable language models.
The ArXiV version can be found in this link, and the link to the code and experiments will be uploaded soon. Another version can be viewed here.
Records of experiments and notes are found in the link below:
These pages are supplemental to the experiments:
One is 1: Analyzing Activations of Numerical Words vs Digits

This is a hackathon project submitted to the Interpretability Hackathon 3.0 (under a similar name; see note on how the projects are ordered on the site). To test for the existence of shared circuits, I compare the activations of analogous numerical sequences, such as the digits “1, 2, 3, 4”, the words “one, two, three, four”, and the months “January, February, March, April”. These findings demonstrate preliminary evidence suggesting that these semantically related sequences share common activation patterns in GPT-2 Small, and allow the construction of a hypothesized circuit that detects and moves numbers, sending relevant information from attention heads to MLPs to obtain the next number or analogous element. The techniques used include activation patching, attention pattern analysis, neuron feature analysis, mean ablation, logit lens, and circuit surgery.
The pdf report can be found in this link, and this is the link to the code and experiments. A short video introducing it is showcased here.
Educational Videos on AI Safety and Neural Network Mathematics
Paper Explanation: Unsupervised Discovery of Semantic Latent Directions in Diffusion Models
This is a video that explains the mathematics behind the paper “Unsupervised Discovery of Semantic Latent Directions in Diffusion Models”, a latent space editing techniques that modifies image styles in diffusion models, such as converting old faces to young faces. The concepts covered include the Pullback, the Jacobian Matrix, Eigenfaces and SVD. They are presented through a science fiction mystery story featuring analog VHS effects. The story revolves around an AI patient is experiencing a puppet show hallucination that appears in their generated images, and how a therapist proposes a method to erase it from their mind.
Why do Neural Networks use Linear Algebra?
This is the first video in a series aimed at a general audience explaining the math behind neural network interpretability. The first video introduces the geometry of latent space for a simple MLP, explaining concepts such as the relations of neurons and feature vectors, basis vectors, dot product, and hypotheses about latent space arithmetic. To be accessible to laymen, it starts with simple multiplication and change of units, gradually extending this to matrix multiplication (see note on the youtube algorithm).
Introduction to Diffusion Model Editing
This video demonstrates Diffusion Model Editing using techniques from Differential Geometry and images from Stable Diffusion. It is aimed at a non-academic audience, combining themes from popular youtube “Analog Horror” videos. It is part of a series of videos intended to introduce generative model editing to a younger, high school aged audience. The following video provides a background explanation of the content in the video:
An expalnation of the among us pareidolia effect
This is an outdated site (to be updated later) explaining concepts similar to ones in the videos above in a blog format:
Making the Math of Neural Networks Intuitive
Machine Learning and Analytics on Social Media Data
Regression Analysis on Video Game Sales using Unstructured Data from Reddit
- Employed web APIs to scrap Reddit posts and semi-structured Wikipedia infoboxes. Cleaned and explored data, then fit models applicable for business decisions in marketing and finance.
Facebook and YouTube Social Network Friend Prediction via SVMs
- Trained Support Vector Machines that achieved high accuracy and AUC scores on testing data. Utilized graph analytics to compare the network statistics of different communities.

Using Materialized Views for Answering Graph Pattern Queries
This dissertation is about developing algorithms to search for patterns in networks using smaller patterns that were already discovered. For example, a knowledge graph may describe entities based on observed features, but not identify them. To search for Shiba Inu, one can input a query with connections to “Japanese”, “long snout” and “pet”. If the dog pattern made of “long snout” and “pet” was already found, it would filter out many wrong candidate entities. These re-usable intermediate results may be pre-computed and stored.
Overall, this work is embedded within the field of graph homomorphism matching, which involves finding subgraph patterns in large datasets, going from local matches (of features) to more global matches (of features). In simple terms, graph homomorphisms “map relationships” between graphs where some connections may be lost or merged, allowing for a more relaxed mapping than graph isomorphisms. These relationship mappings must meet certain types of structure-preserving conditions such as if \(f: A \rightarrow B\) is a relation in system 1, \(h(A) = X\) and \(h(B) = Y\), then \(g: X \rightarrow Y\) is a relation in system 2. This is similar to inference via analogical reasoning.
Analogously, studies found that image recognition neural networks contained neurons that acted as feature detectors, such as ones that are highly activated given inputs of dogs. However, it has been hypothesized that many concepts are stored not just in one neuron, but in sub-networks of neurons, also called circuit motifs, which build into larger motifs. For instance, we can speculate that there may be an abstract dog circuit pattern and a Japanese circuit pattern, and adding more connections between them composes them together into a more specific Shiba Inu circuit.
The concept of universality hypothesizes that “the same circuits will show up in different models”. This means it may be possible to map structures between graphical representations of models. However, these mappings may not be defined using exact graph structures as in a graph isomorphism, but may be defined using analogous functional relations, similar to graph homomorphisms.
Graph pattern matching from local matches to global matches is a technique previously used in other fields of AI, such as in Forbus’s work on analogical pattern matching. This research is connected to the work on AI analogies done by Hofstadter. Recently, the concept of graph homomorphism has been used by Redwood Research to help better formalize experimental methods in the field of neural network interpretability.
This pdf is a trimmed version of the work.
These slides provide a beginner’s introduction to the work.
UNDER CONSTRUCTION:
Analogous Neural Circuit Experiments
Analogous Neural Circuit Experiments aim to find common patterns in neural network activations based on inputs with varying similarities. Why study Analogous Neural Circuit Experiments? These studies enhance Neural Network Interpretability by connecting model predictions to patterns the model uses to make its predictions. This has significant applications, which include:
- Improving Trust in AI: When AI makes important decisions, such as in medical treatment or financial investments, knowing why the AI made those predictions is crucial to ensuring that it is not using faulty reasoning to make its predictions.
- Improving Model Debugging: By uncovering the black box that obscures how neural networks make decisions, practitioners will have more control over debugging neural networks to do what they want.
- Improving Transfer Learning: By understanding which parts of a neural network perform what function, practitioners will be able to dissect neural networks to retrieve the part they need, and apply transfer learning to fine tune that part to suit their own, specific goals.
These experiments are housed in a Github repo with Colab notebooks that walk a reader through how the experiments were conducted. An example of a notebook demonstrating simple experiments is given below:
TUTORIAL 1: Compare Neuron Activations Between Pairs of Images
-
Website in process of being built. Some projects in progress are not added yet and will be added later. ↩